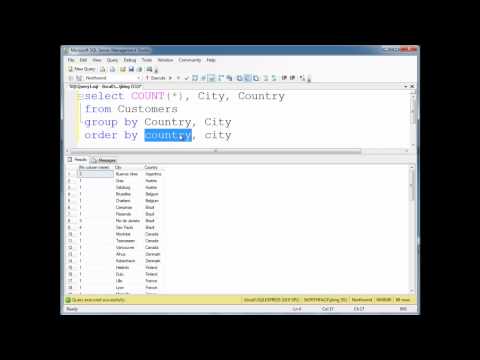
As the name suggests the GROUP BY clause in MySQL groups the data together. The FROM and WHERE clause creates an intermediate tabular result set and the GROUP BY clause systematically groups the data. The GROUP BY clause can group the result set by one or more columns.

That means the Group by Clause divides the similar type of records or data as a group and then returns. If we use group by clause in the query then we should use grouping/aggregate function such as count(), sum(), max(), min(), avg() functions. Expression_n Expressions that are not encapsulated within an aggregate function and must be included in the GROUP BY Clause at the end of the SQL statement.

Aggregate_function This is an aggregate function such as the SUM, COUNT, MIN, MAX, or AVG functions. Aggregate_expression This is the column or expression that the aggregate_function will be used on. There must be at least one table listed in the FROM clause. These are conditions that must be met for the records to be selected. The expression used to sort the records in the result set.

If more than one expression is provided, the values should be comma separated. ASC sorts the result set in ascending order by expression. DESC sorts the result set in descending order by expression.

The GROUP BY clause groups a set of rows into a set of summary rows by values of columns or expressions. In other words, it reduces the number of rows in the result set. In this syntax, you place the GROUP BY clause after the FROM and WHERE clauses. The SQL GROUP BY Statement The GROUP BY statement groups rows that have the same values into summary rows, like "find the number of customers in each country". The GROUP BY statement is often used with aggregate functions (COUNT (), MAX (), MIN (), SUM (), AVG ()) to group the result-set by one or more columns.

The GROUP BY statement groups rows that have the same values into summary rows, like "find the number of customers in each country". The GROUP BY statement is often used with aggregate functions ( COUNT() , MAX() , MIN() , SUM() , AVG() ) to group the result-set by one or more columns. The GROUP BY clause groups identical output values in the named columns.

Every value expression in the output column that includes a table column must be named in it unless it is an argument to aggregate functions. GROUP BY is used to apply aggregate functions to groups of rows defined by having identical values in specified columns. SQL Inner Join permits us to use Group by clause along with aggregate functions to group the result set by one or more columns.

Group by works conventionally with Inner Join on the final result returned after joining two or more tables. The HAVING clause is used instead of WHERE with aggregate functions. While the GROUP BY Clause groups rows that have the same values into summary rows.

The having clause is used with the where clause in order to find rows with certain conditions. The having clause is always used after the group By clause. The GROUP BY clause is a SQL command that is used to group rows that have the same values.

Optionally it is used in conjunction with aggregate functions to produce summary reports from the database. In the result set, the order of columns is the same as the order of their specification by the select expressions. If a select expression returns multiple columns, they are ordered the same way they were ordered in the source relation or row type expression. In this case, the server is free to choose any value from each group, so unless they are the same, the values chosen are nondeterministic, which is probably not what you want. Furthermore, the selection of values from each group cannot be influenced by adding an ORDER BY clause.
Result set sorting occurs after values have been chosen, and ORDER BY does not affect which value within each group the server chooses. You often use the GROUP BY clause with aggregate functions such as SUM, AVG, MAX, MIN, and COUNT. The aggregate function that appears in the SELECT clause provides information about each group. The GROUP BY clause is used in a SELECT statement to group rows into a set of summary rows by values of columns or expressions. The GROUP BY clause defines groups of output rows to which aggregate functions can be applied.

ROLLUP is an extension of the GROUP BY clause that creates a group for each of the column expressions. Additionally, it "rolls up" those results in subtotals followed by a grand total. Under the hood, the ROLLUP function moves from right to left decreasing the number of column expressions that it creates groups and aggregations on.

Since the column order affects the ROLLUP output, it can also affect the number of rows returned in the result set. The Group by clause is often used to arrange identical duplicate data into groups with a select statement to group the result-set by one or more columns. This clause works with the select specific list of items, and we can use HAVING, and ORDER BY clauses. Group by clause always works with an aggregate function like MAX, MIN, SUM, AVG, COUNT. An aggregate function takes multiple rows as an input and returns a single value for these rows. Some commonly used aggregate functions are AVG(), COUNT(), MIN(), MAX() and SUM().

For example, the COUNT() function returns the number of rows for each group. The AVG() function returns the average value of all values in the group. It filters non-aggregated rows before the rows are grouped together. To filter grouped rows based on aggregate values, use the HAVING clause. The HAVING clause takes any expression and evaluates it as a boolean, just like the WHERE clause. As with the select expression, if you reference non-grouped columns in the HAVINGclause, the behavior is undefined.

Otherwise, each column referenced in the SELECT list outside an aggregate function must be a grouping column and be referenced in this clause. All rows output from the query that have all grouping column values equal, constitute a group. If you don't use GROUP BY, either all or none of the output columns in the SELECT clause must use aggregate functions. If all of them use aggregate functions, all rows satisfying the WHERE clause or all rows produced by the FROM clause are treated as a single group for deriving the aggregates. Like most things in SQL/T-SQL, you can always pull your data from multiple tables. Performing this task while including a GROUP BY clause is no different than any other SELECT statement with a GROUP BY clause.

The fact that you're pulling the data from two or more tables has no bearing on how this works. In the sample below, we will be working in the AdventureWorks2014 once again as we join the "Person.Address" table with the "Person.BusinessEntityAddress" table. I have also restricted the sample code to return only the top 10 results for clarity sake in the result set. The above query includes the GROUP BY DeptId clause, so you can include only DeptId in the SELECT clause.

You need to use aggregate functions to include other columns in the SELECT clause, so COUNT is included because we want to count the number of employees in the same DeptId. You must use the aggregate functions such as COUNT(), MAX(), MIN(), SUM(), AVG(), etc., in the SELECT query. The result of the GROUP BY clause returns a single row for each value of the GROUP BY column. In the Group BY clause, the SELECT statement can use constants, aggregate functions, expressions, and column names.
Having Clause is basically like the aggregate function with the GROUP BY clause. You can also use the having clause with the Transact-SQL extension that allows you to omit the group by clause from a query that includes an aggregate in its select list. These scalar aggregate functions calculate values for the table as a single group, not for groups within the table. Here, you can add the aggregate functions before the column names, and also a HAVING clause at the end of the statement to mention a condition. The GROUP BY clause is often used with aggregate functions such as AVG(), COUNT(), MAX(), MIN() and SUM().
In this case, the aggregate function returns the summary information per group. For example, given groups of products in several categories, the AVG() function returns the average price of products in each category. It is not permissible to include column names in a SELECT clause that are not referenced in the GROUP BY clause.

The only column names that can be displayed, along with aggregate functions, must be listed in the GROUP BY clause. Since ENAME is not included in the GROUP BYclause, an error message results. Adding a HAVING clause after your GROUP BY clause requires that you include any special conditions in both clauses.

How To Use Group By After Where Clause In Sql If the SELECT statement contains an expression, then it follows suit that the GROUP BY and HAVING clauses must contain matching expressions. It is similar in nature to the "GROUP BY with an EXCEPTION" sample from above. In the next sample code block, we are now referencing the "Sales.SalesOrderHeader" table to return the total from the "TotalDue" column, but only for a particular year. The aggregate functions allow you to perform the calculation of a set of rows and return a single value.

The GROUP BY clause is often used with an aggregate function to perform calculations and return a single value for each subgroup. When you start learning SQL, you quickly come across the GROUP BY clause. Data grouping—or data aggregation—is an important concept in the world of databases. In this article, we'll demonstrate how you can use the GROUP BY clause in practice. We've gathered five GROUP BY examples, from easier to more complex ones so you can see data grouping in a real-life scenario. As a bonus, you'll also learn a bit about aggregate functions and the HAVING clause.

SQL allows the user to store more than 30 types of data in as many columns as required, so sometimes, it becomes difficult to find similar data in these columns. Group By in SQL helps us club together identical rows present in the columns of a table. This is an essential statement in SQL as it provides us with a neat dataset by letting us summarize important data like sales, cost, and salary.

The SELECT statement used in the GROUP BY clause can only be used contain column names, aggregate functions, constants and expressions. When selecting groups of rows from the database, we are interested in the characteristics of the groups, not individual rows. Therefore, we often use aggregate functions in conjunction with the GROUP BY clause.

That means the first Group By clause is used to divide similar types of data as a group and then an aggregate function is applied to each group to get the required results. This statement is used to group records having the same values. The GROUP BY statement is often used with the aggregate functions to group the results by one or more columns.

In this query, all rows in the EMPLOYEE table that have the same department codes are grouped together. The aggregate function AVG is calculated for the salary column in each group. The department code and the average departmental salary are displayed for each department. When you use a GROUP BY clause, you will get a single result row for each group of rows that have the same value for the expression given in GROUP BY. As you can see in the result set above, the query has returned all groups with unique values of , , and .

The NULL NULL result set on line 11 represents the total rollup of all the cubed roll up values, much like it did in the GROUP BY ROLLUP section from above. Another extension, or sub-clause, of the GROUP BY clause is the CUBE. The CUBE generates multiple grouping sets on your specified columns and aggregates them.

In short, it creates unique groups for all possible combinations of the columns you specify. For example, if you use GROUP BY CUBE on of your table, SQL returns groups for all unique values , , and . IIt is important to note that using a GROUP BY clause is ineffective if there are no duplicates in the column you are grouping by.

A better example would be to group by the "Title" column of that table. The SELECT clause below will return the six unique title types as well as a count of how many times each one is found in the table within the "Title" column. FILTER is a modifier used on an aggregate function to limit the values used in an aggregation. All the columns in the select statement that aren't aggregated should be specified in a GROUP BY clause in the query.

However, you can use the GROUP BY clause with CUBE, GROUPING SETS, and ROLLUP to return summary values for each group. Having can be used without groupby clause,in aggregate function,in that case it behaves like where clause. Groupby can be used without having clause with the select statement. This syntax allows users to perform analysis that requires aggregation on multiple sets of columns in a single query. Complex grouping operations do not support grouping on expressions composed of input columns. JOINS are SQL statements used to combine rows from two or more tables, based on a related column between those tables.



